
A few weeks ago, Ian Agol, Vlad Markovic, Ursula Hamenstadt and I organized a “hot topics” workshop at MSRI with the title Surface subgroups and cube complexes. The conference was pretty well attended, and (I believe) was a big success; the organizers clearly deserve a great deal of credit. The talks were excellent, and touched on a wide range of subjects, and to those of us who are mid-career or older it was a bit shocking to see how quickly the landscape of low-dimensional geometry/topology and geometric group theory has been transformed by the recent breakthrough work of (Kahn-Markovic-Haglund-Wise-Groves-Manning-etc.-) Agol. Incidentally, when I first started as a graduate student, I had a vague sense that I had somehow “missed the boat” — all the exciting developments in geometry due to Thurston, Sullivan, Gromov, Freedman, Donaldson, Eliashberg etc. had taken place 10-20 years earlier, and the subject now seemed to be a matter of fleshing out the consequences of these big breakthroughs. 20 years and several revolutions later, I no longer feel this way. (Another slightly shocking aspect of the workshop was for me to realize that I am older or about as old as 75% of the speakers . . .)
The rationale for the workshop (which I had some hand in drafting, and therefore feel comfortable quoting here) was the following:
Recently there has been substantial progress in our understanding of the related questions of which hyperbolic groups are cubulated on the one hand, and which contain a surface subgroup on the other. The most spectacular combination of these two ideas has been in 3-manifold topology, which has seen the resolution of many long-standing conjectures. In turn, the resolution of these conjectures has led to a new point of view in geometric group theory, and the introduction of powerful new tools and structures. The goal of this conference will be to explore the further potential of these new tools and perspectives, and to encourage communication between researchers working in various related fields.
I have blogged a bit about cubulated groups and surface subgroups previously, and I even began this blog (almost 4 years ago now) initially with the idea of chronicling my efforts to attack Gromov’s surface subgroup question. This question asks the following:
Gromov’s Surface Subgroup Question: Does every one-ended hyperbolic group contain a subgroup which is isomorphic to the fundamental group of a closed surface of genus at least 2?
The restriction to one-ended groups is just meant to rule out silly examples, like finite or virtually cyclic groups (i.e. “elementary” hyperbolic groups), or free products of simpler hyperbolic groups. Asking for the genus of the closed surface to be at least 2 rules out the sphere (whose fundamental group is trivial) and the torus (whose fundamental group 

First let’s start with the precise definition of a random group. There are actually two parameters in the definition — the density 

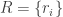

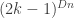

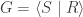
Gromov introduced random groups and established some of their basic properties. One talks about a random group at density 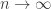
Theorem (Gromov): A random group has the following properties with overwhelming probability:
1. At 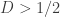
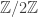
2. At 
3. At 
The story at density 
With this definition, the main theorem Alden and I prove is the following:
Theorem (Calegari-Walker): A random group at density 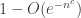
In particular, they contain surface subgroups with overwhelming probability. In fact, at the MSRI conference I gave a partial announcement of this theorem, saying only that we could prove the existence of surface subgroups at “some positive density”; I was worried about the fact that at density 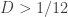

The proof contains some technical details, but I believe that some of the main ideas of the proof can be given in a blog post. But before I do so, I think it is worth discussing (very) briefly why one might be interested in finding surface subgroups.
For certain classes of hyperbolic groups — for example, fundamental groups of hyperbolic 3-manifolds — finding a surface subgroup was always known to be an important question to give insight into the virtual Haken conjecture. In fact, the Kahn-Markovic construction of such subgroups turned out to be one of the key steps in the eventual proof of that conjecture by Agol. But even beyond 3-manifolds per se, surface subgroups play an important role. At the MSRI conference Vlad Markovic talked about an approach he has to Cannon’s Conjecture — which says if 
I do not remember exactly my motivations and heuristic evidence in favor of the existence of “many surface groups in many hyperbolic groups” except for connectedness arguments at the boundaries, but I had (and am having) a feeling that these are essential structural components of hyperbolic groups.
My own view, and my main interest in this question, is stimulated by a belief that surface groups (not necessarily closed, and possibly with boundary) can act as a sort of “bridge” between hyperbolic geometry and symplectic geometry (through their connection to causal structures, quasimorphisms, stable commutator length, etc). Surface groups are the “simplest” kind of hyperbolic groups after free groups, and surfaces themselves are the “simplest” class of symplectic manifold; any route between the two kinds of geometry must surely say a lot about surfaces. In this vein, I should remark that in the world of 3-manifold topology (where these issues are infinitely better understood), surfaces again play the premier role in both worlds: minimal/pleated/shrinkwrapped surfaces in the hyperbolic world, norm minimizing/pseudoholomorphic/convex in the contact/symplectic world. It is worth remarking that for the longest time embedded surfaces played a preeminent role in both theories, but that recent breakthroughs (on the hyperbolic side) have depended on developing a deep understanding of immersed surfaces. I wonder whether there is an important role for immersed surfaces on the symplectic side (in 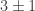
OK, let’s move on to the proof of the Random Group Surface Subgroup Theorem. The first step of the proof builds on a construction in our paper Surface subgroups from Linear Programming, where we show that a sufficiently random homologically trivial collection of cyclic words in a free groups can be taken to bound a certain kind of combinatorial object called a Folded Fatgraph (this result also underpins the main theorem in my recent related paper Random graphs of free groups contain surface subgroups, joint with Henry Wilton). A fatgraph is just an ordinary graph together with a choice of cyclic ordering on the edges incident to each vertex. Such a graph can be canonically fattened to a compact surface (with boundary) in which it lies as a spine. Stallings famously observed that an immersion (i.e. a locally injective simplicial map) between graphs is injective on fundamental groups; such a map of graphs is said to be folded. Thus a folded fatgraph gives an injective surface (with boundary!) subgroup of a free group with prescribed boundary.
The first step in our paper is to make this result more quantitative. A trivalent fatgraph with reduced boundary words is necessarily folded. Our first main result is the following
Thin Fatgraph Theorem: If 



These fatgraphs have very long edges and are trivalent; hence are “thin”. Let me not say anything about the proof except that the first part of it closely models the proof of Thm 8.9 from our SSLP paper linked above, but the last step (which was done by computer in the SSLP paper) depends on an elementary but complicated combinatorial argument (which takes up almost half the paper!). (It is worth remarking that this last combinatorial step has something morally in common with the Kahn-Markovic proof of the Ehrenpreis conjecture via the theory of “good pants homology”, in that we want to cancel some collection of “superfluous” short loops which can be thought of as random excitations on the surface of a (Dirac) sea of perfectly equidistributed loops. I should also remark that some version of this theory — “pants homology” if you will — was earlier developed by me in my paper Faces of the scl norm ball, in which I showed that every homologically trivial immersed collection of geodesics on a hyperbolic surface virtually cobounds an immersed subsurface with a sufficiently large multiple of the boundary.)
By the way, it is natural to wonder just how “random” the collection

The first time we did this experiment, we only looked at words up to length 50 or so; needless to say, this gives a somewhat misleading idea of the asymptotic picture!
How can one use thin fatgraphs to build surface subgroups? Before tackling a random group, let’s consider a one-relator group with a single (long, random) relator 
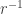

The first thing one might think therefore is that one should just apply the Thin Fatgraph Theorem to build a fatgraph bounding 

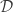



A counting estimate gives the following heuristic answer. By the defining property of a Thin Fatgraph, for any 
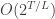
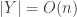
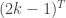
Explicitly, we find what we call a Bead Decomposition of 
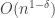


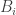


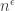

We now throw in an additional 



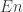
One subtlety is that it is necessary to control the size of the van Kampen diagrams we consider independently of 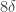


Is there anything that can be said about the index of these surface subgroups?
Yes: they’re certainly of infinite index.